
Empilhamento 3D de GPUs e Memórias HBM: o Guia Completo
O mercado de computação de alto desempenho vive um ponto de inflexão. A cada trimestre, modelos de inteligência artificial maiores e mais famintos por largura de banda esbarram em limitações de energia, espaço físico e, sobretudo, temperatura. Nesse cenário, o empilhamento 3D de GPUs e memórias HBM desponta como a solução mais promissora para extrair densidade computacional sem ampliar a área ocupada na placa. Entretanto, empilhar silício não é uma mera questão de “encaixe de blocos Lego”. O calor, as correntes elétricas e a integridade mecânica inauguram um novo livro de regras de projeto.
Neste guia, vamos dissecar cada camada—literalmente—dessa arquitetura. Você aprenderá:
- Por que chegamos ao limite do layout 2.5D.
- Como o empilhamento 3D altera latência, largura de banda e densidade.
- Quais são os principais gargalos térmicos e elétricos.
- Estratégias práticas de mitigação, do design de interposer ao resfriamento.
- Impactos econômicos para data centers e tendências de mercado.
Se você é engenheiro, gestor de TI ou entusiasta de hardware que busca entender onde a indústria realmente está e para onde vai, este é o conteúdo definitivo.
1. Por que chegamos ao limite do 2.5D
Durante a última década, o layout 2.5D — em que a GPU central e até oito empilhamentos de HBM são dispostos lado a lado sobre um interposer de silício — dominou servidores e aceleradores de IA. Esse formato diminui a distância física entre processador e memória, reduz a latência e fornece até 1 TB/s de largura de banda, valores impressionantes para padrões de 2020.
Contudo, há três fatores que tornaram o 2.5D insuficiente em 2024:
- Pressão de espaço em data centers: racks são cobrados por U, e cada centímetro cúbico precisa ser convertido em TFLOPs. Placas maiores significam menos máquinas por rack.
- Demanda de modelos de IA: LLMs explodiram a necessidade de largura de banda. Mesmo HBM3, com 819 GB/s por pilha, pode se tornar gargalo quando você empilha múltiplas GPUs por módulo.
- Escalonamento de custos: interposers maiores exigem retículas mais largas, encarecendo a produção e reduzindo rendimento por wafer.
Ou seja, seguir crescendo “para os lados” já não fecha a conta nem física nem financeiramente. A alternativa lógica passa a ser empilhar “para cima”.
2. O que muda quando migramos para o empilhamento 3D
2.1 Latência e largura de banda
Colocar a HBM diretamente sobre a GPU elimina milímetros de trilhas de cobre. Parece pouco, mas em sinais de gigahertz, cada milímetro reduz estabilidade e eleva consumo energético de I/O. Ao empilhar verticalmente, microprotuberâncias (microbumps) com pitch de 20–40 µm encurtam o caminho do elétron de dezenas de milímetros para frações. Na prática:
- Largura de banda chega a escalar 1,5–2× em relação ao 2.5D, mantendo a mesma frequência de I/O.
- A latência, medida em nanosegundos, cai de 5–7 ns para menos de 3 ns entre GPU e camada DRAM mais próxima.
Esse ganho é crítico para inferências em tempo real (voz, chat, streaming) e para treinamentos distribuídos onde cabos ópticos já impõem atrasos na ordem de microssegundos.
2.2 Ganho de densidade
O número mais usado para justificar o salto 3D é “performance por área”. Ao sobrepor pilhas de 8 a 12 dies de DRAM sobre o processador, economiza-se até 45% da área total de substrato. Na prática, um fabricante pode:
- Entregar o dobro de aceleradores por placa ocupando o mesmo slot PCIe.
- Diminuir o número de racks no data center para um mesmo throughput.
- Reduzir o caminho de alimentação de energia, mitigando perdas resistivas.
Porém, todo ganho de densidade vem acompanhado de uma nova variável limitante: a temperatura.
3. O vilão invisível: gestão térmica em arquiteturas verticais
3.1 Como o calor se comporta num sanduíche de silício
O silício é um moderado condutor térmico, com cerca de 150 W/m·K. Isso é razoável quando o calor dissipa na horizontal. Mas, num empilhamento 3D, as camadas inferiores (a GPU, por exemplo) se tornam “ilhas térmicas” cercadas por material igualmente quente. Como o calor tende a subir, as camadas de DRAM viram tampas que travam a convecção natural.
Em testes de laboratório com cargas de IA intensivas, observou-se:
- Picos de 140 °C no topo da pilha, mesmo com soluções de resfriamento de 400 W.
- Diferenças de até 70 °C entre empilhamento 3D e o mesmo chip em 2.5D, sob idêntica refrigeração.
- Pontos quentes localizados (hotspots) correspondentes a matrizes de multiprocessadores ativas no momento.
Temperaturas acima de 105 °C afetam não só a confiabilidade, mas também a retenção de dados na DRAM (que depende de circuitos de sensing extremamente sensíveis). Portanto, controlar o calor deixa de ser “boa prática” e se torna requisito de viabilidade.
3.2 Ferramentas de simulação e mapeamento de hotspots
A engenharia térmica moderna começa antes do primeiro wafer ser produzido. Softwares de CFD (Computational Fluid Dynamics) e FEA (Análise de Elementos Finitos) são usados para prever a distribuição de temperatura camada a camada. Três indicadores guiam o processo:
- Tjmax por die: temperatura máxima de junção para não comprometer a vida útil.
- Rθ ja: resistência térmica do componente ao ambiente.
- GTI (Global Thermal Index): métrica composta que integra temperatura, gradiente e tempo de exposição.
Ao mapear hotspots, a equipe de projeto pode redistribuir macros de lógica, adicionar vias térmicas ou mesmo reorganizar as camadas de memória (ex.: colocar um die DRAM “dummy” de interface térmica sobre a região mais quente).
4. Estratégias de mitigação: do design ao cooler
4.1 Interposers inteligentes e microbump
Você pode reduzir a temperatura simplesmente diminuindo a resistência térmica interna. Interposers de silício com canais de cobre embutidos (through-silicon vias, ou TSVs) funcionam como “canudos” de calor, conduzindo energia para áreas mais frias ou diretamente para um dissipador. Além disso, soldas de microbump feitas de ligas com alta condutividade (ex.: AuSn) atuam como micro-dissipadores.
4.2 Redução de clock e escalonamento dinâmico
Outra tática contraintuitiva: baixar o clock do die central. Experimentos mostraram que cortar a frequência da GPU de 1,6 GHz para 800 MHz diminuiu o pico térmico de 120 °C para menos de 100 °C, mantendo performance/área superior ao 2.5D. É uma troca matemática: menos Hz individuais, porém mais unidades no mesmo volume. Os algoritmos de IA, muitas vezes bound por largura de banda, sofrem pouco quando a lógica escala horizontalmente.
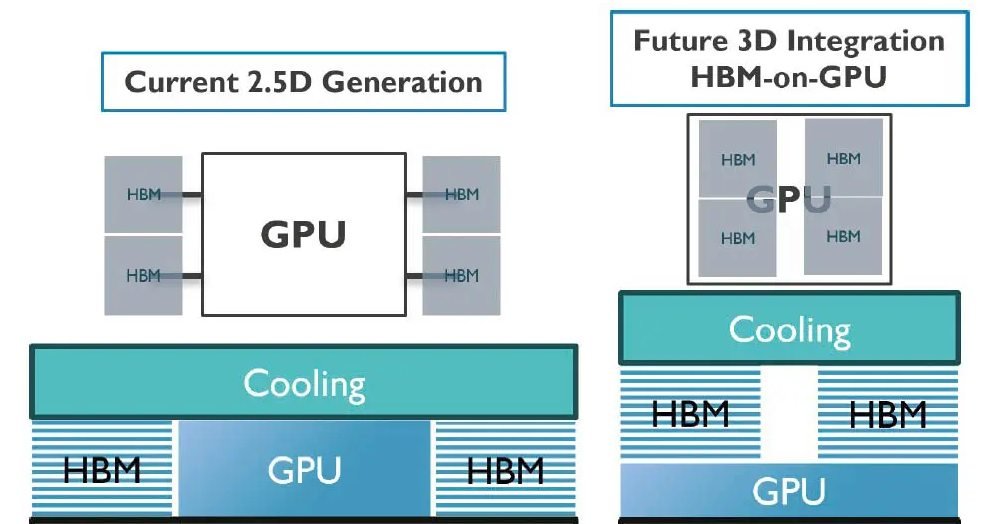
Imagem: William R
Em produção, isso se traduz em DVFS (Dynamic Voltage and Frequency Scaling) governado por firmware: o chip reduz tensões em milissegundos quando sensores detectam temperatura crítica, voltando a frequências máximas assim que possível.
4.3 Resfriamento bilateral e soluções líquidas
Se o calor sobe, ataque por cima e por baixo. Dispositivos de resfriamento bilateral instalam um cold plate na base do pacote, extraindo calor diretamente do interposer, enquanto um segundo bloco cobre o topo da pilha de HBM. A circulação líquida (água, água glicol ou dielétricos como 3M Novec) leva a condutividade térmica efetiva para valores na casa dos 4000 W/m·K.
Alguns protótipos chegam a empregar jet impingement, microjatos direcionados de líquido sobre regiões específicas do silício, criando coeficientes de transferência acima de 300 000 W/m2·K, algo impossível de atingir com ar forçado.
4.4 Materiais de interface avançados
Há ainda o mundo dos TIMs (Thermal Interface Materials): pastas com partículas de metal líquido ou grafeno, folhas de diamante sintético CVD, e até soldas de fase única. Esses materiais podem reduzir a resistência de contato em 30–40%, significando vários graus Celsius a menos no hotspot.
4.5 Modelagem holística: co-projeto elétrico-térmico
Por fim, vale enfatizar que calor e eletricidade são dois lados da mesma moeda. Correntes maiores geram I²R maior, que gera calor — que, por sua vez, aumenta a resistividade do cobre e piora a perda. Grandes fabricantes já adotam co-design eletrotérmico: o layout do VRM, a posição dos conectores de alimentação e a malha de GND são otimizados em conjunto com as vias térmicas, garantindo menor delta entre bleeder e load.
5. Impacto no ecossistema de IA e data centers
5.1 CapEx versus OpEx
A adoção de empilhamento 3D eleva o CapEx inicial. O processo de manufatura requer:
- Equipamentos de bonding alinhados na casa de < 2 µm.
- Inspeção ótica 3D para cada camada.
- Passos extras de planarização e metalização.
Estimativas colocam o custo por unidade 30–50% acima de um módulo 2.5D equivalente. Entretanto, o OpEx (custo operacional) tende a cair por três razões:
- Mais desempenho por watt, reduzindo a pegada de energia por tarefa.
- Menos espaço físico por TFLOP, diminuindo aluguel e refrigeração ambiente.
- Maior densidade resulta em menor cabeamento e manutenção.
Para empresas hyperscale, o payback pode acontecer em menos de dois anos, principalmente quando o hardware roda inferências 24/7.
5.2 Sustentabilidade e eficiência energética
Data centers globais já consomem cerca de 1,3% da eletricidade mundial. Qualquer vantagem de eficiência é alavancada em escala planetária. Chips 3D reduzem perdas de I/O, diminuem clock necessário e permitem usar resfriamento líquido mais eficaz (que, por sua vez, pode ser integrado a trocadores para aquecimento predial). A meta de muitas cidades é recuperar de 20 a 40% do calor dissipado em data centers; arquiteturas 3D ajudam ao concentrar calor em pontos de fácil captura.
5.3 Possibilidades de design de placas
Empilhando memórias em cima da GPU, abre-se espaço na PCB para:
- Módulos de alimentação mais robustos, aumentando eficiência de conversão.
- Interfaces ópticas integradas (CPO ‑ Co-Packaged Optics), eliminando transceivers externos.
- Componentes de rede NVLink, permitindo topologias mesh completas no mesmo slot.
6. Roadmap e tendências para os próximos cinco anos
Apesar dos resultados promissores, a indústria ainda endereça três marcos antes de massificar o 3D:
- HBM4 e Beyond: novos padrões prometem interface de 6,4 Gb/s por pin, elevando ainda mais a densidade de I/O. Os dies terão que empregar empilhamento híbrido, com interposer ativo de lógica de controle.
- Cooling as a Service: provedores de nuvem devem oferecer racks com circuitos de água quente (≈50 °C) e sistemas de recuperação de calor integrados. O hardware 3D será desenhado já pensando em loop fechado.
- Fotônica embarcada: ao aproximar dies, a limitação elétrica cobre apenas distâncias curtas. Para backplane ou inter-rack, lasers on-chip resolvem latência sem aquecer tanto quanto cobre de alta velocidade.
Em paralelo, universidades e consórcios, como o 3D-HiPEAC, investigam integração heterogênea: CPU, GPU, HBM, NVRAM e até aceleradores quânticos compactos, todos empilhados. O maior desafio será garantir que uma falha em um die não inviabilize o pacote inteiro, ponto em que a reparabilidade em wafer (wafer-level repair) se torna mandatória.
Conclusão
O empilhamento 3D de GPUs e memórias HBM não é moda passageira; trata-se de uma resposta inevitável aos limites físicos de largura de banda e área de placa. Embora o calor represente um muro de tijolos, técnicas de co-design, resfriamento bilateral, materiais avançados e escalonamento dinâmico já demonstraram derrubar esse muro a níveis gerenciáveis.
Em essência, perdemos alguns MHz, mas ganhamos quilômetros de densidade. Para operadores de data center, isso se traduz em mais projetos de IA por rack, menor custo operacional e, paradoxalmente, menor pegada ambiental. Para engenheiros, inaugura-se uma época de colaboração multidisciplinar: térmica, elétrica, mecânica e software precisam conversar desde o diagrama de blocos até o firmware de DVFS.
Se você pretende investir, projetar ou simplesmente entender o futuro do processamento de IA, acompanhe de perto as evoluções em empilhamento 3D. A física impôs novos limites; a engenharia já começa a negociá-los.

